Dans le document “Understanding data protection : the EU regulation in a nutshell” (Comprendre la protection des données : le règlement européen en quelques mots) ci-dessus, la minimisation des données était motivée par la réduction du gain de pouvoir du responsable du traitement à ce qui est minimalement nécessaire pour réaliser les finalités déclarées et légitimes. En particulier, elle vise à minimiser le contenu informatif des données personnelles traitées. Cela complète la minimisation du degré d’association des données avec la personne concernée et la limitation de l’accès au pouvoir. Voir “Minimisation du pouvoir à ce qui est nécessaire pour réaliser les finalités déclarées” pour plus de détails.
Le RGPD définit ce principe comme suit :
| Définition de l’art. 5(1)(c) du RGPD :
Les données à caractère personnel doivent être adéquates, pertinentes et limitées à ce qui est nécessaire au regard des finalités pour lesquelles elles sont traitées (“minimisation des données“) ; |
Évidemment, cela n’est possible que si ces finalités sont spécifiques et explicites (comme l’exige l’art. 5(1)(b) du RGPD).
Adéquat, pertinent et limité
Adéquat et pertinent sont faciles à comprendre : Les données inadéquates, c’est-à-dire impropres aux finalités, ne peuvent être collectées ou traitées ; les données doivent également être pertinentes, c’est-à-dire qu’elles doivent servir les finalités.
Pour comprendre l’aspect de la limitation, un regard plus précis sur la signification réelle des données est nécessaire. En particulier, il est intuitivement clair que ce n’est pas seulement le nombre d’éléments de données qui est concerné ici, mais le contenu informatif réel des données. Les paragraphes suivants illustrent ce point en relation avec les finalités :
- Sélection : Lorsqu’un ensemble d’éléments de données possibles est envisagé, il faut sélectionner ceux qui sont nécessaires aux fins visées. Notez que si les données sont déjà stockées, la sélection peut également être comprise comme la suppression d’éléments de données inutiles. Sinon, elle concerne les données qui sont effectivement collectées.
- Résolution : Lorsque les données sont disponibles à plusieurs résolutions possibles, limitez la résolution à ce qui est le moins nécessaire pour l’objectif visé. Par exemple :
- Valeurs : exprimez les valeurs à l’échelle la plus grossière possible tout en respectant les objectifs,
- par exemple, utilisez une catégorie d’âge (40-59 ans, résolution de 20 ans) au lieu d’une date de naissance (résolution d’un jour),
- Emplacements : exprimez les emplacements en termes de subdivision géographique la plus grossière possible,
- par exemple, utiliser des unités administratives telles que des zones de code postal ou des provinces ou encore des cellules de grille aulieu de coordonnées précises (d’une résolution de plusieurs mètres),
- Série temporelle : exprime des séries temporelles de données au taux d’échantillonnage le plus grossier qui permette de réaliser les finalités fixées,
- cela peut nécessiter un rééchantillonnage des données obtenues à partir d’un capteur,
- Empreintes digitales : Si vous devez uniquement comparer des ensembles de données pour vérifier leur égalité, envisagez de traiter une certaine “empreinte digitale” des données.
- Par exemple, une “valeur de hachage cryptographique” (alias “condensé”) des données peut être suffisante pour détecter les modifications[1] .
- Valeurs : exprimez les valeurs à l’échelle la plus grossière possible tout en respectant les objectifs,
- Niveau d’agrégation : Dans la mesure du possible, choisissez un niveau d’agrégation adéquat. La plupart des valeurs de données que nous traitons sont une forme d’agrégation, même si cela n’est pas évident puisqu’elle peut être effectuée de manière “invisible” par un capteur ou une méthode de collecte de données. L’agrégation est une manière de substituer plusieurs éléments de données par un seul. Les exemples les plus frappants proviennent des statistiques et comprennent la moyenne, la médiane, le minimum et le maximum. Dans le contexte de la protection des données, il convient de distinguer deux types d’agrégation :
- Personne unique : Agrégation des éléments de données relatifs à une seule personne :
- Prendre par exemple le revenu moyen d’une personne sur une année réduit le contenu de l’information relative à cette personne.
- Personnes multiples : Agrégation d’éléments de données se rapportant à une multitude de personnes :
- Prendre par exemple le revenu annuel moyen d’un groupe de personnes réduit également le contenu global de l’information (minimisation des données). En outre, cela affaiblit également le degré d’association entre un élément de données et une personne donnée. Ce type d’agrégation est donc également pertinent pour la limitation du stockage (voir section )
- Personne unique : Agrégation des éléments de données relatifs à une seule personne :
Aspect temporel
Il est clair que la minimisation des données comporte également un aspect temporel. Surtout, “limité à ce qui est nécessaire au regard des finalités” signifie également qu’il n’est plus justifié de conserver des données lorsque les finalités ont déjà été réalisées. Les données doivent donc être supprimées dès qu’elles ne sont plus nécessaires.
Dans la pratique, cela peut être encore plus diversifié : Parmi les finalités (au pluriel), certaines peuvent être réalisées plus tôt que d’autres. De même, après le “traitement principal”[2] , un “traitement ultérieur à des fins d’archivage dans l’intérêt public, à des fins de recherche scientifique ou historique ou à des fins statistiques”[3] peut avoir lieu. Pour modéliser cela, nous distinguons plusieurs phases de traitement. La figure suivante tente de visualiser cette situation.
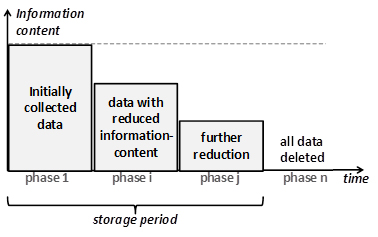
Figure 3: Réduction du contenu de l’information en plusieurs étapes.
En particulier, la figure montre un exemple avec quatre phases. Un nombre quelconque de phases est possible. Comme chaque phase est associée à un sous-ensemble de finalités, à la fin de chaque phase, lorsque les finalités respectives ont été réalisées, certaines données ne sont plus nécessaires. Par conséquent, à la fin de chaque phase, certaines données peuvent être supprimées (sélection), ou leur contenu informatif peut être réduit (réduction de la résolution ou augmentation du niveau d’agrégation). Il est évident qu’une telle approche diversifiée minimise davantage les données qu’une approche à phase unique qui conserve l’intégralité du contenu informatif jusqu’à ce que toutes les finalités aient été réalisées.
- Pour plus d’informations sur les condensés cryptographiques, voir par exemple https://en.wikipedia.org/wiki/Cryptographic_hash_function (dernière visite le 15/5/2020). ↑
- Le terme “traitement principal” est utilisé ici pour faire la distinction avec le “traitement ultérieur”. ↑
- Le libellé a été directement copié de l’art. 5(1)(b) du RGPD. ↑