In Understanding data protection: the EU regulation in a nutshell above, data minimization was motivated by minimizing the power gain of the controller to that what is minimally necessary to fulfill the declared, legitimate purposes. In particular, it addressed the minimization of information content present in the processed personal data. This complements the minimization of the degree of association that the data have with the data subject, and the limitation of access to power. See Minimization of power to what is necessary to fulfill the declared purposes for detail.
The GDPR defines the principle as follows:
| Definition in Art.5(1)(c) GDPR:
Personal data shall be adequate, relevantand limited to what is necessary in relation to the purposes for which they are processed (‘data minimization’); |
Evidently, this is only possible is these purposes are specified and explicit (as required in Art. 5(1)(b) GDPR).
Adequate, relevant and limited
Adequate and relevant are easy to understand: Data that is inadequate, i.e., unfit for the purposes, cannot be collected or processed; the data must also be relevant, i.e., it must serve the purposes.
To understand the limitation aspect, a more precise look at what data actually means is necessary. In particular, It is intuitive clear that not just the number of data elements is concerned here, but the actual information content of the data. The following shall illustrate this in relation to the purposes:
- Selection: Where a set of possible data elements is under consideration, select those that are necessary for the purposes. Note that if data is already stored, selection can also be understood as deletion of unnecessary data elements. Otherwise it is concerned with data that is actually collected.
- Resolution: Where data is available at multiple possible resolutions, limit the resolution to what is minimally necessary for the purposed. For example:
- Values: express values at the coarsest scale that still supports the purposes,
- for example, use an age category (40-59 years old, 20 year resolution) instead of a date of birth (one day resolution),
- Locations: express locations in terms of the coarsest geographic subdivision possible,
- for example, use administrative units such as postal code zones or provinces or grid cells instead of precise coordinates (of meters in resolution),
- Time Series: express time series of data at the coarsest sampling rate that still supports the purposes,
- this may require a resampling of the data obtained from some sensor,
- Fingerprints: If you need to only compare data sets for equality, consider just processing some “fingerprint” of the data.
- For example, a “cryptographic hash value” (aka. “digest”) of the data may be sufficient to detect change[1].
- Values: express values at the coarsest scale that still supports the purposes,
- Level of Aggregation: Where possible, chose an adequate level of aggregation. Most of the data values we deal with are a form of aggregation, even if this may not be evident since it may be done “invisibly” by some sensor or data collection method. Aggregation is a way of substituting several data elements by a single one. Prime examples come from statistics and include the average, median, minimum, and maximum. In the context of data protection, two kinds of aggregation have to be distinguished:
- Single Person: Aggregation of data elements pertaining to a single person:
- Taking for example a person’s average income over a year reduces the information content pertaining to that person.
- Multiple Persons: Aggregation of data elements pertaining to a multitude of persons:
- Taking for example the average yearly income over group of persons also reduces the overall information content (data minimization). In addition, it also weakens the degree of association between a data element and a given person. This kind of aggregation is therefore also pertinent to storage limitation (see Storage limitation section)
- Single Person: Aggregation of data elements pertaining to a single person:
Temporal aspect
Data minimization clearly also has a temporal aspect. Most importantly, “limited to what is necessary in relation to the purposes” also means that it is no longer justified to store data when the purposes have already been fulfilled. Data therefore has to be deleted as soon as it is no longer necessary.
In practice, this may be even more diversified: Of the purposes (plural), some may be fulfilled earlier than others. Also, after the “main processing”[2], “further processing for archiving purposes in the public interest, scientific or historical research purposes or statistical purposes”[3] may take place. To model this we distinguish several phases of processing. The following figure attempts to visualize this situation.
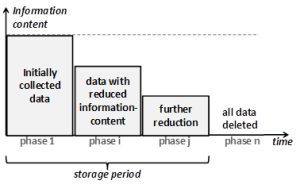
Figure 3: Reduction of information content in multiple steps.
In particular, the figure shows an example with four phases. Any number of phases is possible. Since every phase is associated with a subset of purposes, at the end of each phase, when the respective purposes have been fulfilled, certain data is no longer necessary. Consequently, at the end of each phase, certain data can be either deleted (selection), or its information content can be reduced (reduction of resolution or increase of level of aggregation). It is evident that such a diversified approach minimizes data further than a single-phase approach that keeps the full information content until all purposes have been fulfilled.
References
1For further information about cryptographic digests, see for example, 1https://en.wikipedia.org/wiki/Cryptographic_hash_function (last visited 15/5/2020). ↑
2The term “main processing” is used here to distinguish from “further processing”. ↑
3The wording was directly copied from Art. 5(1)(b) GDPR. ↑