For a better understanding of anonymous, it is helpful to look at how it is different from (strictly) pseudonymous. This is done in the present section.
The following table shows the two definitions side by side. It annotates the differences.
| Definition: Anonymous data
Data is anonymous if any possible actor is unable to directly or indirectly(re-)identify data subjects with means reasonably likely to be used now or in the future. |
Definition: Strictly pseudonymous data
Data is strictly pseudonymous in the context of pseudonymization, if, in presence of the technical and organizational measures of the pseudonymization, the intended recipients are unable to directly identify data subjects. |
The following differences are evident:
- While the definition of anonymous is general, strictly pseudonymous data is only defined in the limited context of pseudonymization with its technical and organizational measures.
- While the definition of anonymous refers to arbitrary actors, that of strictly pseudonymous data limits the actors to intended recipients.
- While the definition of anonymous refers to both, direct and indirect identification, that of strictly pseudonymous data limits itself to direct identification.
- While the definition of anonymous addresses the time of processing as well as the future beyond, strictly pseudonymous data limits addresses considers only the time of processing. In other words, while anonymous uses an open temporal horizon, strictly pseudonymous uses a limited temporal horizon.
Note that the definition of anonymous explicitly states that only means reasonably likely to be used have to be considered. This is not explicitly stated in the definition of strictly pseudonymous, but it is implied by the context of pseudonymization. So there is no difference in this point.
This can be summarized by stating that both pseudonymization and anonymization have the objective of preventing the identification of data subjects; the former does so in a controlled environment, while the latter is more ambitious by doing so in general.
Note that anonymous data are also strictly pseudonymous since the requirements for being strictly pseudonymous are a subset of the requirements for being anonymous.
The following two figures illustrate the difference between strictly pseudonymous and anonymous. First, Figure 18 shows the case of pseudonymization where the facilitating elements of the environment are shown in green. Then, Figure 19 shows the case of anonymization with the more demanding elements highlighted in red.
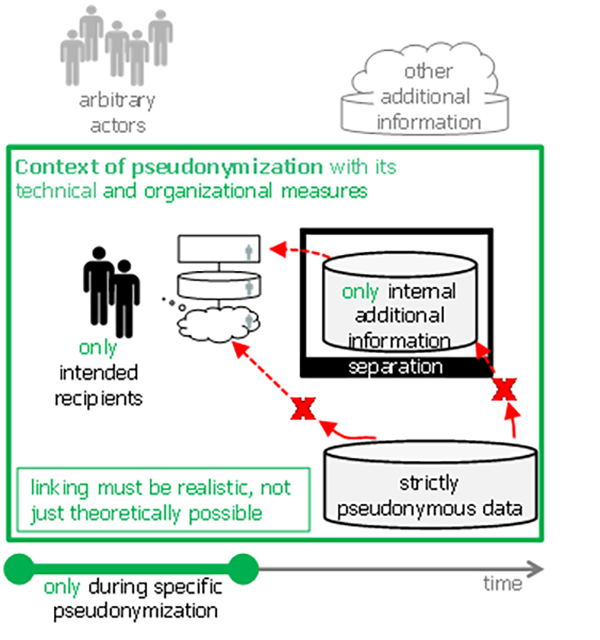
Figure 18: Data that is pseudonymous in the context of a specific pseudonymization (i.e., processing activity).
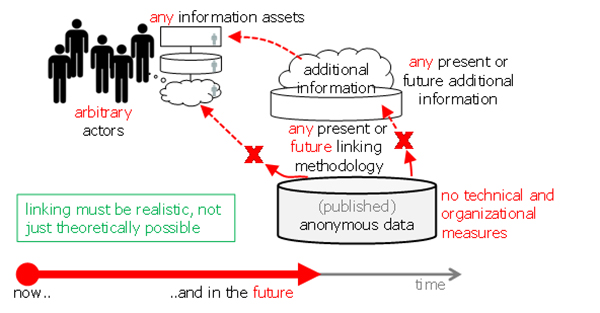
Figure 19: Anonymous data.