This section discusses the functional implementation of anonymization as a subset of that of data pseudonymization. The functionality of successful and attempted anonymizationare identical.
Functionally, anonymization is implemented by appropriate transformations which reduce the identification potential of the personal data (see section 3.3 above). The reduction is considered sufficient, when the “success state” of no longer being able to identify data subjects has been reached.
Since also data pseudonymization is also implemented by transformations which reduce the identification potential, Figure 22 illustrates the relationship between anonymization and data pseudonymization. In particular, it shows that anonymization is functionally equivalent to the processing step (iv) of data pseudonymization. The difference lies solely in the degree of reduction of the identification potential. This was already discussed above when comparing the two “success states”.
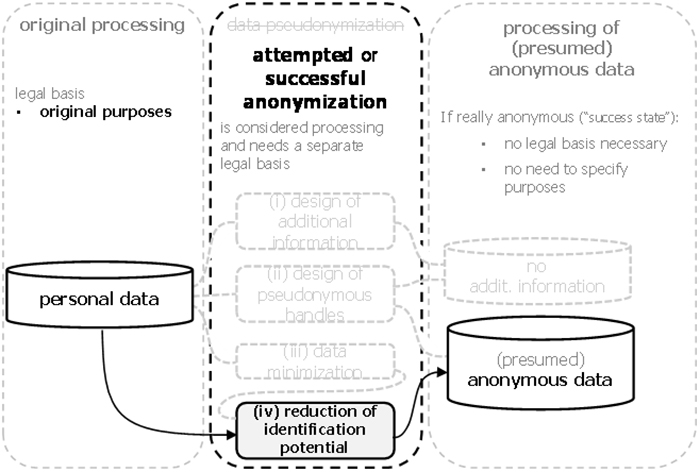
Figure 22: Anonymization as a functional subset of data pseudonymization.
It was argued earlier that the functionality of data pseudonymization is not sufficient to guarantee that the resulting data is strictly pseudonymous, i.e., that it does no longer permit the direct identification of data subjects. In the same way, the functionality of attemptedanonymization does not guarantee that the “success state” of anonymous is actually reached.
Section 3.3.4 above describes how the available transformations reduce the identification potential gradually and that it is usually impossible to find clear indicators to determine whether the “success state” has been reached. This results in an uncertainty whether the data resulting from attemptedanonymization are indeed anonymous, or, if the “success state” has not been reached, still personal.