The following establishes a vocabulary of precisely defined terms that enable to make precise statements about identification, pseudonymization, and anonymization.
This subsection is designed to be read at different levels of detail. In its minimal use, it can be totally skipped and used only as a glossary when the need arises to better understand terms used in later sections. Instead of reading the full text, it is possible to abbreviate the reading by considering only the definition boxes. For brevity, this short version avoids to incorporate the discussion of how the concepts relate to the GDPR; readers interested in that aspect are referred to the more detailed analysis at https://uldsh.de/PseudoAnon.
The discussion of pseudonymization and anonymization focuses on (personal) information.
| Definition: information
Information consists of expressions of facts represented either in the form of
It also includes meta-information about data sets, such as information about how these have been created and how the persons described by the data have been selected. |
Of particular interest is individual-level information.
| Definition: individual-level information
Individual-level information is information, where information elements can be attributed to a single person (i.e., an individual). In statistics, this is often called micro data. Since individual-level information relates to a person, it is personal information. |
Individual-level information is closely related to a data record.
| Definition: data record
A data record is a subset of a data set that contains all information elements related to a single person. |
Personal information is composed of information elements.
| Definition: information element
Information elements are components of a single data record. They can either be single data values (such as the “age”) or tuples of values (such as a postal address) that can be broken up further into smaller data elements (such as street name, street number, postal code, and town. |
The following types of information elements often take on different roles in the context of pseudonymization and anonymization:
| Definition: unique handle
A unique handle is an information element, such as a string or number, with the purpose of referring to a single entity (such as a person) within a pre-defined set of possible entities. Every entity in the set has exactly one handle; the handles of two distinct entities of the set are always different. A unique handle can be seen as an artefact created by an actor as a representation of the identity of an entity. |
Examples for unique handles include the following:
- First names (given names) given by parents to their children. They are unique in the core family. Should the same first name already be used by other persons in the core family, “tie breakers” such as junior, senior, the first, or the second are typically used to render the name unique. Middle names may serve the same purpose.
- Nicknames for people in a group of friends. Nicknames are often used for friends who have the same given name to distinguish them in the group.
- Family names for families living in small communities such as villages where these names were likely unique at the time of assignment.
- Customer numbers assigned by a company to its customers.
- Username or online-identifier.
- E-mail addresses. The assignment of the username component is under the control of the e-mail provider and enforced to be unique. The domain component of the e-mail address then represents the e-mail provider and is guaranteed to be globally unique based on the management of domains by the global organization of the Internet domain name registry. E-mail addresses are thus an example for a globally unique handle.
- Unique handles that represent the identity of devices, such as phone numbers, MAC Addresses, serial numbers, etc.
- Unique handles that represent the identity of vehicles such as license plate numbers or the vehicle identification number.
- A postal address that typically relates to a unique letter box.
- An IBAN or account number of a bank account.
Since unique handles are only unique in a given context, it is practical to establish a term to denote this context:
| Definition: identity domain
An identity domain is a context consisting of a group of eligible entities (sometimes called eligible population), and an actor (called domain owner) who is responsible for issuing unique handles, and a procedure to determine the handle of a given entity. Handles in a given identity domain are designed to be unique. |
Note that unique handles are sometimes also be used outside of their identity domain. This, for example, is routinely the case for names (first and family name). When used outside of the domain where they were assigned, they are not guaranteed to be unique any longer.
| Definition: non-unique handle
A non-unique handle is an originally unique handle that is used outside of its identity domain and is therefore no longer guaranteed to be unique. It often has the identification characteristics of a quasi-identifier. |
Transformations to reduce the identification potential of data (often misleadingly called “anonymization techniques”) often assign a special role to quasi-identifiers.
| Definition: quasi-identifier
A quasi-identifier is composed of one or a combination of information elements that are unique for at least a significant number of persons contained in a data set. |
The term is extensively used in the context of “anonymization techniques” such as generalization or anatomization (see below). The term is also used by the Art. 29 Data Protection Working Party in their Opinion on Anonymization Techniques[1] but without a clear definition.
Typical examples for quasi-identifiers are the following:
- Name, gender, date and place of birth[2];
- 5-digit ZIP, gender, and date of birth[3];
- Mobility data[4];
- Certain kinds of biometrics, such as fingerprints (depending on the size of the candidate population across which it should be close to unique),
- Certain kinds of genetic data, such as DNA (which is unique except in the case of identical twins), or short tandem repeats on the Y chromosome[5].
The third major type of information element (after unique handle and quasi-identifier) is an identity-relevant property that is defined in the following:
| Definition: identity-relevant property
An identity-relevant property is a combination of information elements that has the potential to be unique at least for one or a few persons. This definition is very similar to that of a quasi-identifier. The difference lies in the “power” of identification. In particular, an identity-relevant property may be unique only for rare combinations of values for only one or few persons of a candidate set. |
Since unique combinations of values are often unexpected, it is a safe approach to consider any property that is related to a person, the person’s activities and expressions, or any entity closely related to a person as an identity-relevant property. This seems in line with the GDPR’s wording of “one or more factors specific to the physical, physiological, genetic, mental, economic, cultural or social identity of that natural person”[6].
A simple example that illustrates identity-relevant properties is eye color. It is usually not thought of being identifying, since the common eye colors are shared by large number of persons. However, red is one of the possible eye colors[7] and is so rare[8] that it could easily identify a single individual.
While red eye color is very rare worldwide, other properties may be very rare in certain countries or regions. For example, Jewish confession is rather rare in Iran or blond hair is rare in certain Asian countries.
While in these simple examples, the rareness may initially be unexpected, it then becomes rather evident. In contrast, rareness may often be more difficult to recognize and understand in larger and more complex combinations of information elements.
Unique combinations can also be present in little structured data sets. A well-known example for this is the “anonymized” search history published by AOL. Based among others on place and family names contained in the searches of an initially pseudonymous user (AOL Searcher No. 4417749), the person behind it could be re-identified[9].
Uniqueness seems to be very common in so-called high-dimensional data sets[10].
| Definition: dimension of a data set
The dimension of an individual-level data set is simply the number of attributes that it contains for each person. In a tabular representation of the data set, it corresponds to the number of columns (where rows are data records linked to a single individual). |
In high-dimensional data sets, every attribute in the data set is considered to be a dimension of its own. For every dimension, an axis can be imagined. Attribute values can then be seen as coordinates along one of the axes. Every actual data record (that is composed of a tuple of attribute values) can then be seen as a point in this multi-dimensional space.
In this setting, the uniqueness of a data record can be understood as the distance between the data record (as a point in space) to its closest neighbors (i.e., data records represented as points). If a data point is far from all other data points, it is rather unique; if it is part of a cluster of points that are mutually close, it is far less unique. Obviously, the more unique a data record is, the more potential it has to identify a data subject.
In this context, it has been argued[11] that the higher the dimension of a data set, i.e., the more attributes it contains, the more likely it is that at least some data records are highly unique. The reasoning behind this is that when a data record is close to others looking only at a subset of attributes, it is likely to distinguish itself from these records in the other attributes. This pattern becomes more likely with increasing dimension of the data set. In other words, finding points that are close when considering all attributes becomes less likely with increasing number of attributes.
Also the Article 29 Data Protection Working Party emphasizes the identification potential of high-dimensional data in their Opinion on Anonymization Techniques[12]. It also provides an example where the identification of data subjects was possible due to the uniqueness of data records in a high-dimensional data set. Namely, this is the well-publicized identification of persons in the Netflix Prize dataset, which contains anonymous movie ratings of 500,000 subscribers of Netflix[13] that was linked against the Internet Movie Database.
The concept of identification is closely related to that of linking.
| Definition: linking
The objective of linking is to obtain information about how data records (or single attributes) of one data set or information collection relate to the data records of another one. |
What kind of linking is possible depends on the kind of attribute value. Therefore we distinguish two kinds of values:
| Definition: discrete value
A discrete value is expressed on a scale that is based on a pre-defined set of possible values. Examples for discrete values are nominal values (such as names, strings, or colors) and integer numbers (such as a year). Discrete values can be compared by checking on equality. |
| Definition: continuous value
A continuous value is expressed on a scale on which there exists an infinite number of values between any two values. Continuous values are for example measurements expressed on a ratio scale or as real (floating point) numbers (such as blood pressure or weight). The comparison of continuous values is based on the notion of difference[14]. When continuous values are the result of measurement or observation, they are typically subject to limited precision, accuracy, and random errors. The concept of equality of two continuous values therefore does not exist: continuous values can be similar, close, or correlated. |
Based on this distinction of values, two types of linking can be distinguished. The first kind of linking is based on equality of discrete values:
| Definition: deterministic linking
Deterministic linking establishes relationships between data records of distinct data sets based on the comparison of discrete information elements for equality. |
Deterministic linking is illustrated in Figure 1:
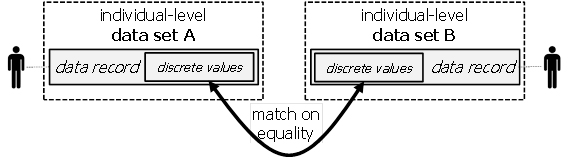
Figure 1: Deterministic linking.
When the discrete values that are compared act as identifiers for the person, the matches are expected to be unique, i.e., a data record in one data set matches exactly one data record in the other.
When the discrete values do not uniquely identify individuals, matching may be ambiguous. In this case, a data record of one data set may match several data records in the other data set (and vice-versa). Assuming in both data sets, distinct data records belong to distinct persons, such ambiguity introduces uncertainty: instead of finding the matching person in the other data set, a possibly small set of “candidates” is found. Often, such uncertainty can be removed or further reduced in additional steps by matching with additional data sets.
The second kind of linking is based on the similarity, proximity, or correlation of continuous values:
| Definition: probabilistic linking
Probabilistic linking establishes relationships between data records of distinct data sets based on the comparison of continuous values for similarity, proximity, or correlation. |
Probabilistic linking is illustrated in Figure 2:
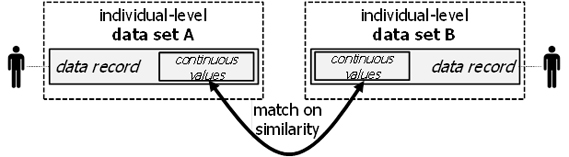
Figure 2: Probabilistic linking.
Probabilistic linking is typically based on continuously valued quasi-identifiers or identity-relevant properties. A precise match with equal values in both data sets is highly unlikely. Therefore, only a closeness, similarity, or correlation of the values can be determined. The resulting relation between data records in the different data sets is therefore not Boolean (i.e., “belong to the same person”, “belong to different persons”). In fact, the relation expresses a probability that the data records actually belong to the same person.
Note that linking by comparison of the same attribute values in two data sets is only the most common case. There are other linking methods, as for example models that establish the degree of correlation between different kinds of attributes in the data sets. Such models could for example be created though machine learning.
References
1Article 29 Data Protection Working Party, WP 216, Opinion 05/2014 on Anonymisation Techniques, Adopted on 10 April 2014, https://ec.europa.eu/justice/article-29/documentation/opinion-recommendation/files/2014/wp216_en.pdf (last visited 24/06/2021). ↑
2This combination is for example used in some national unique schemes for unique handles such as the Italian tax number. ↑
3See for example: L. Sweeney, Simple Demographics Often Identify People Uniquely. Carnegie Mellon University, Data Privacy Working Paper 3. Pittsburgh 2000, https://dataprivacylab.org/projects/identifiability/paper1.pdf (last visited 5/11/2020). ↑
4See for example: de Montjoye, Y., Hidalgo, C., Verleysen, M. et al. Unique in the Crowd: The privacy bounds of human mobility. Sci Rep 3, 1376 (2013). https://doi.org/10.1038/srep01376 ↑
5See Melissa Gymrek; Amy L. McGuire; David Golan; Eran Halperin; Yaniv Erlich (18 January 2013), “Identifying personal genomes by surname inference”, Science, 339 (6117), Bibcode:2013Sci…339..321G, doi:10.1126/SCIENCE.1229566, PMID 23329047, Wikidata Q29619963. ↑
6Art. 4 (1) GDPR . ↑
7See for example, Rebecca E., Rare Human Eye Colors, Sciencing, Updated July 20, 2018, https://sciencing.com/rare-human-eye-colors-6388814.html (last visited 10/11/2020). ↑
8Red eyes seem to be related to albinism and Wikipedia states that in Europe and the United States, the prevalence of albinism is about 1 in 20’000 (see https://en.wikipedia.org/wiki/Albinism_in_humans#Epidemiology, last visited 10/11/2020). ↑
9/sup>See Michael Barbaro and Tom Zeller Jr., A Face Is Exposed for AOL Searcher No. 4417749, New York Times, August 10, 2006, https://archive.nytimes.com/www.nytimes.com/learning/teachers/featured_articles/20060810thursday.html (last visited 10/11/2020). ↑
10See for example, Aggarwal, Charu C. (2005). “On k-Anonymity and the Curse of Dimensionality”. VLDB ’05 – Proceedings of the 31st International Conference on Very large Data Bases. Trondheim, Norway. CiteSeerX 10.1.1.60.3155. ISBN 1-59593-154-6, http://www.charuaggarwal.net/privh.pdf (last visited 10/11/2020). ↑
11See for example, Aggarwal, Charu C. (2005). “On k-Anonymity and the Curse of Dimensionality”. VLDB ’05 – Proceedings of the 31st International Conference on Very large Data Bases. Trondheim, Norway. CiteSeerX 10.1.1.60.3155. ISBN 1-59593-154-6, http://www.charuaggarwal.net/privh.pdf (last visited 10/11/2020). ↑
12See page 30 in, WP216, footnote 3. ↑
13Arvind Narayanan, Vitaly Shmatikov: Robust De-anonymization of Large Sparse Datasets. IEEE Symposium on Security and Privacy 2008:111-125, https://doi.org/10.1109/SP.2008.33, https://www.cs.utexas.edu/~shmat/shmat_oak08netflix.pdf (last visited 15/12/2020). ↑
14The difference is usually defined in terms of a distance function. ↑