The following describes a typical procedure of how to perform data pseudonymization. In other words, it describes the steps to construct a tuple of strictly pseudonymous data and split-off additional information starting from identified data. It depicts the common case where the identified data was previously used for other purposes. Pseudonymization could then constitute “further processing” (see Art. 5(1)(b) and 89(1) GDPR) that pursues its own purposes.
The overall procedure of data pseudonymization is illustrated in Figure 16 and discussed in the following.
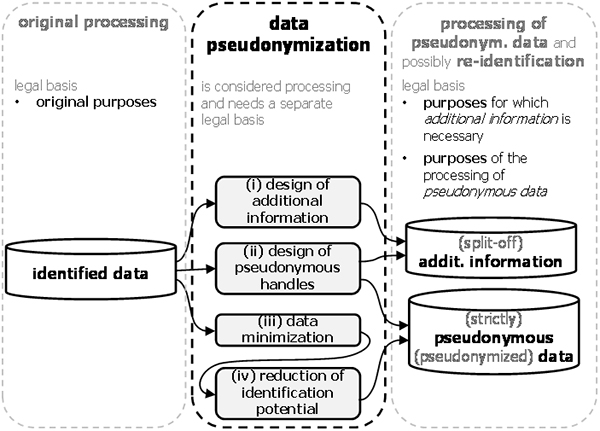
Figure 16: Functional details of data pseudonymization.
Preparatory step: In the preparatory step, controllers need to specify the purposes pursued by the pseudonymization, i.e., the processing after data pseudonymization. This includes:
- the purposes for keeping (split-off) additional information and
- the purposes pursued by the processing of (strictly)pseudonymous data.
Clarity about these purposes is important to guide several processing steps of data pseudonymization.
This is most evident in the data minimization[1] step (iii), since it filters out all data and detail that is unnecessary to fulfill the stated new purposes.
It is similarly crucial to the step of design of additional information (i). More precisely, this step can be seen as a variation of data minimization: Identifying data elements within the additional information can be kept only if they are necessary for legitimate purposes. A precise specification of these purposes is therefore an important input into the data pseudonymization procedure. This will be explained further below.
In the sequel, the actual processing steps that constitute data pseudonymization are described:
(i) Design of additional information: Controllers have to make certain design-decisions about the additional information. This task is guided by the purposes for which additional information is necessary in the first place.
(a) A first decision that controllers need to make is whether their purposes require the storage of additional information at all. This is most often equivalent with the question of whether re-identification of data subjects is necessary. Another reason for which additional information is necessary is to handle incremental growth of personal data that affects already existing data subjects.
If additional information is unnecessary for the purposes, data minimization and storage limitation (see Art. 5(1)(c) and (e) GDPR) mandate that no additional information be kept. Note that Art. 11 GDPR states that it is not necessary to store additional information for the sole purpose of complying with requirements of the GDPR, such as the implementation of data subject rights.
(b) Once established that additional information is indeed necessary, controllers need to decide whether it has to be one- or bi-directional. When re-identification is necessary, the additional information must always be bi-directional. When an incremental growth of personal data has to be handled, it is sufficient that the additional information is one-directional. Data minimization and storage limitation (see Art. 5(1)(c) and (e) GDPR) mandate that one-directional rather than bi-directional additional information shall be used if it is sufficient for the purposes.
(c) One further decision is which directly identifying data elements shall be used for the additional information.
Assume for example, that the additional information shall be used in rare cases to re-identify data subjects in order to contact them. This may be the case, for example, when processing pseudonymous health data that may reveal that a specific data subject suffers from certain medical conditions that require rapid medical attention or intervention. The controller then needs the additional information in support of the purpose of contacting the affected data subjects. Consequently, the identifying data elements should be those suited to establish such contact (such as a telephone number or e-mail address).
In another example, assume that an external processor received pseudonymous data for analysis and that the result of the analysis has then be re-identified by the controller for further processing. In this case, the identifying data element should be the unique handle that is used in the processing of the identified data.
(ii) Design of pseudonymous handles: This step affects both, the split-off additional information and the strictlypseudonymous data since pseudonymous handles are part of both. The decision to make here is how to actually create the pseudonymous handles. A definition of the concept of pseudonymous handles was given in the previous section; different methods for creating pseudonyms were discussed in section above. In summary, pseudonyms can be created independently (e.g., as random numbers) or derived from certain identifying data elements (e.g., by using a cryptographic one-way function or encryption). The present step of data pseudonymization decides which is the most suitable method to use.
(iii) Data minimization: The identified data were designed to support a set of original purposes. The processing step of data minimization eliminates all data that are no longer necessary for the new purposes pursued by the processing of the strictly pseudonymous data. This could entail both, the elimination of complete data elements, or the reduction of detail though generalization. An example for the latter is to generalize a precise locations (represented by latitude and longitude coordinates) to larger areas (such as a ZIP area or a county).
Note that while functionally, data minimization may be indistinguishable from the reduction of identification potential (i.e., step (iv), see below), they are conceptionally distinct: the former reduces information content since it is no longer necessary to fulfill the new purposes; the latter may use the same transformations in order to prevent direct identification of individuals through the linking of data. Data minimization is listed here explicitly since certain data elements may be free of any risk of linking, but anyhow have to be removed during data pseudonymization.
(iv) Reduction of identification potential: The strictly pseudonymous data are constructed by reducing the identification potential of the identified data. This is achieved by applying appropriate transformations to reduce the identification potential of the identified data set until the resulting data cease to permit the direct identification by the intended recipients (see definition of strictlypseudonymous data above).
Section 3.3 above has provided an overview of transformations that reduce the identification potential. In summary, the most important are possibly deletion, generalization, slicing to reduce the dimensionality, and noise injection. These belong to both, the category of
- truthful transformations which reduce the level of detail in the data, and
- transformations that introduce deviations from the truth (i.e., errors).
Some typical examples of transformations used during data pseudonymization shall illustrate the concept:
- Typically, all unique handles must be deleted[2].
- Quasi-identifiers that permit direct recognition of persons must be either generalized or deleted.
- Unique values and unique combinations of identity-relevant properties have to be transformed with methods such as generalization, error injection, top-coding, or deletion.
As was illustrated above in section 3.3.4, these transformations gradually reduce the identification potential of the data. In particular, they gradually delete more data elements, reduce the level of detail contained in the data, or add noise (i.e., error) to impede linking. So the key question is how much identification potential needs to be reduced until direct identification is no longer possible.
As follows from the definition of strictly pseudonymous data, this question can be answered in the well-defined context of the pseudonymization at hand, including its technical and organizational measures and its intended (internal or external) recipients of the strictlypseudonymous data.
Once the recipients are identified, controllers need to assess what information assets are reasonably likely[3] available to them. These information assets can include the following:
- Other data kept by the controller for other processing activities that is also accessible[4] to the personnel with access to the strictlypseudonymous data at hand,
- possibleknowledge about data subjects in the head of personnel (for example when they process data pertaining to close acquaintances), and
- external data that is readily available[5] to the personnel (as for example data that can easily be looked up on the Internet from the work place).
The question of whether the identification potential is reduced sufficiently to reach strict pseudonymity now boils down to whether the available identified information assets can be linked to the strictly pseudonymous data. Having identified these information assets and knowing the content of the strictly pseudonymous data, this becomes a well-defined task[6]. Since only the linking methodology that is reasonably likely used[7] by the known actors (i.e., intended recipients) has to be considered, complex linking methods can often be excluded. Organizational measures that prohibit[8] personnel to attempt any linking may further exclude possibilities of identification.
References
1Note that data minimization is one of the principles of data protection (see Art. 5(1)(c) GDPR). ↑
2Note that the pseudonymous handle is not present in the identified data but only created during data pseudonymization. ↑
3The term “reasonably likely” is used on Recital 26, sentence 3, GDPR in a comparable context. The assessment of available assets must take the implemented technical and organizational measures into account. ↑
4In case such other data exists but is not accessible to the personnel working with the pseudonymous data, the controller must obviously be appropriate technical and organizational measures to deny such access. ↑
5While this data is certainly physically external and could therefore be considered to be “additional information”, it seem reasonable to include this data. After all, its access may be possible from the work place and may be seamless and indistinguishable from the access of local data. ↑
6In particular, the task of determining whether data is indeed strictly pseudonymous is easy in comparison of determining whether data is anonymous (see below). This is due to the fact that the former determination is made in a very well-defined context, while the latter must consider any (realistically) possible context and thus introduces significant uncertainty. ↑
7See Recital 26, sentence 3, GDPR. ↑
8This can for example be achieved through a contractual agreement and reinforced through training. ↑