There are different kinds of (re-)identifying data subjects in pseudonymous data. The various possibilities are illustrated in Figure 24. They are described in more detail in the extended version of this analysis (see https://uldsh.de/PseudoAnon).
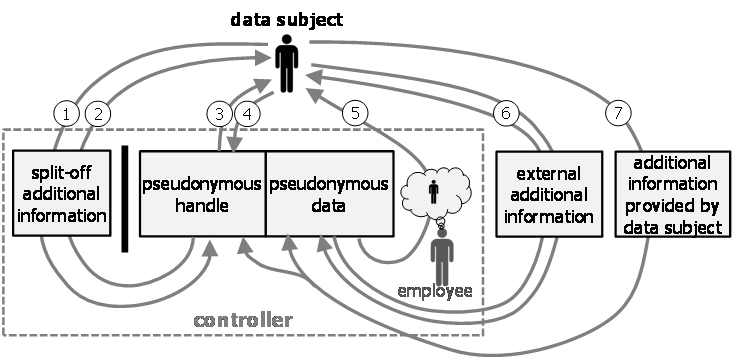
Figure 17: Different types of identification from the point of view of the controller.
The various kinds of identification are described in the following:
- Locating pseudonymous data record associated with a given data subject.
- Locating a data subject associated with a given pseudonymous data record.
- Pseudonym inversion attack.
- Pseudonym creation attack for known data subjects.
- Unexpected recognition of data subject by personnel.
- Indirect identification attack though the linking with external additional information.
- Locating a pseudonymous data record based on additional information provided by the data subject.
Note that the above two cases, (3) and (4), of (re-)identification are possible without the use of additional information. Strictly speaking, this means that the data that was called “pseudonymous data” are in fact not (strictly) pseudonymous in the legal sense. These kinds of identification should thus never occur in practice. If they are anyhow possible, it is likely due to flaws in the processing design.