To be able to make precise statements about pseudonymization, this subsection defines some important concepts (terms).
This subsection is designed to be read at different levels of detail. In its minimal use, it can be totally skipped and used only as a glossary when the need arises to better understand terms used in later sections. Instead of reading the full text, it is possible to abbreviate the reading by considering only the definition boxes. For brevity, this short version avoids to incorporate the discussion of how the concepts relate to the GDPR; readers interested in that aspect are referred to the more detailed analysis (see https://uldsh.de/PseudoAnon).
| Definition: Data pseudonymization
Data pseudonymization is a transformation that takes identified data as input and creates two output data sets, namely pseudonymous data and additional information, respectively. |
Data pseudonymization is illustrated in Figure 7.
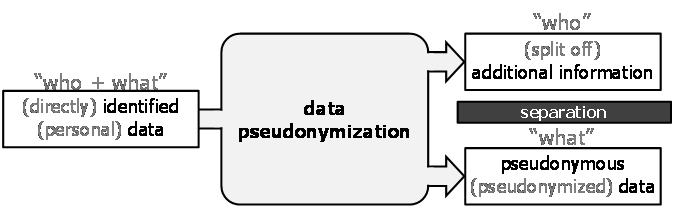
Figure 7: Data pseudonymization.
| Definition: (General) re-identification
Re-identification in the general sense is a transformation that takes pseudonymous dataand additional information as input and creates identified data as output. The concept is general and de-coupled from pseudonymization in the sense that the additional information is not limited to that resulting from data pseudonymization and stored by the controller. In fact, anyadditional information can be used, including and most commonly that existing outside of the controller. |
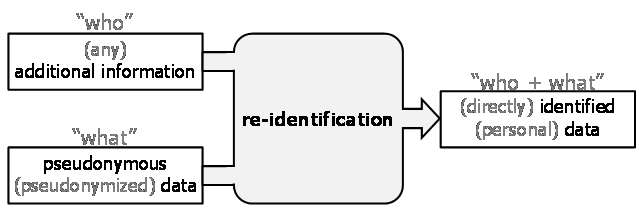
Figure 8: General re-identification.
| Definition: Planned re-identification
Planned re-identification is the special case of re-identification where the additional information is that resulting from data pseudonymization and stored by the controller. |
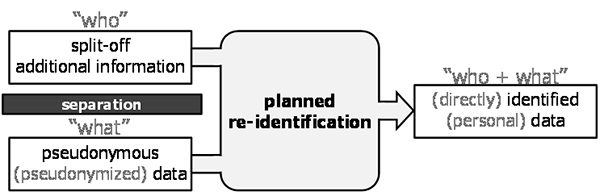
Figure 9: Planned re-identification.
| Definition: (Directly) identified[1] (personal) data
Directly identified personal data, or more shortly identified data, is personal data that allows direct identification of data subjects. This is the case, for example, when the data includes names or commonly used unique handles. The term is synonym to the expression “personal data relating to an identified data subject”. It implies that the data can be directly linked to information assets in possession of the actor who identifies (see section on identification above). |
The concept of identified personal data is illustrated in Figure 10.
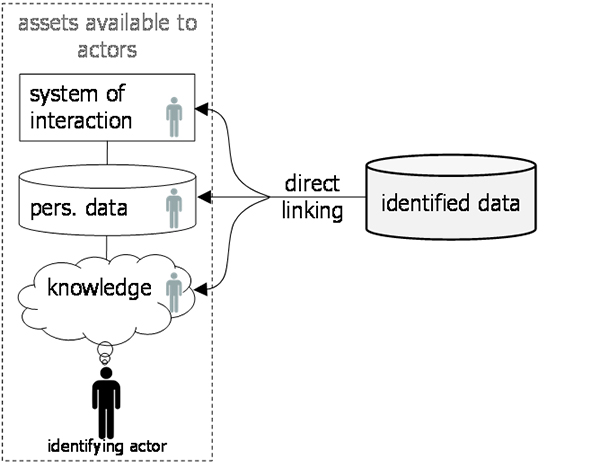
Figure 10: Identified data.
Within the concept of pseudonymous data, two types are distinguished:
| Definition: (General) pseudonymous data [captures the common use of the term]
General pseudonymous data, or simply pseudonymous data, is datathat refrains from containing any directly identifying data elements (“identifiers”) such as names, commonly used unique handles, or common quasi-identifiers. |
| Definition: Strictly pseudonymous data [captures the use of the term in the GDPR]
Data is strictlypseudonymous in the context of pseudonymization, if, in presence of the technical and organizational measures of the pseudonymization, the intended recipients are unable to directly identify data subjects. In absence of these measures, indirect identification using additional information is still possible. Strictly pseudonymous data is a special case of (general) pseudonymous data that satisfies the stricter requirements implied by Art. 4(5) GDPR. |
Note that this text predominantly discusses strictly pseudonymous data. Being a special case of (general) pseudonymous data, it is still correct to call them simply pseudonymous data. This has been done excessively in this text. It also applies to the labels of pseudonymous data in many figures above. When the simplified version of the concept is used, it should be clear from the context provided by the text, that the discussion is concerned with strictly pseudonymous data. This is basically always the case in this text, unless where it is explicitly stated that it deals with general pseudonymous data.
The concept of strictly pseudonymous data is further illustrated in Figure 11.
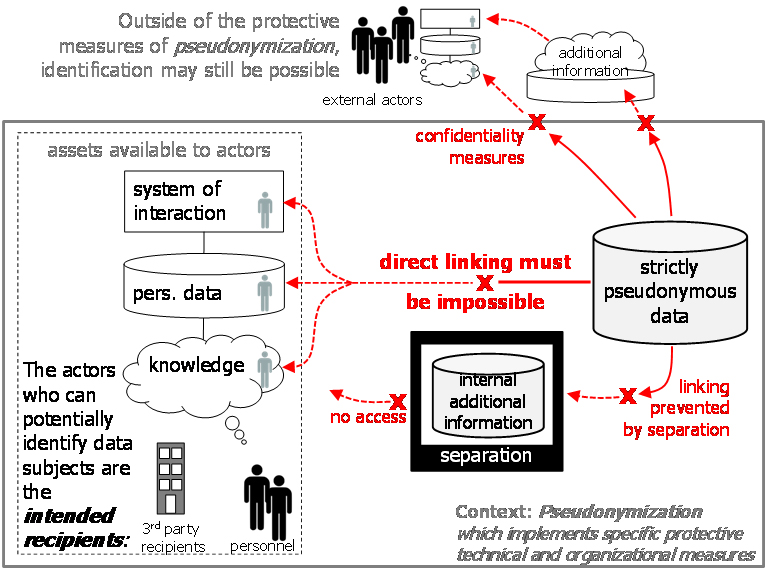
Figure 11: In the context of pseudonymization, intended recipients are unable to identify data subjects in strictly pseudonymous data.
| Definition: Pseudonymized data
Pseudonymized data is strictly pseudonymous data that is created as an output of data pseudonymization. |
Note that strictly pseudonymous data is not always the result of data pseudonymization. For example, data can be collected in a manner such that it is already strictly pseudonymous. This includes for example to refrain from collecting directly identifying data elements and manage potentially unique attribute values. For this reason, pseudonymized data is not used exclusively, but the more general concept of strictly pseudonymous data is still necessary.
The concept of additional information was already defined in the context of (indirect) identification above and is further specialized here in the context of pseudonymization. Two types of additional information are distinguished based on their relationship to pseudonymization:
| Definition: (General) additional information
Additional information is knowledge or data that can be used for indirect identification of at least one data subject in pseudonymous data. For that purpose, the additional information must establish a relation between
The latter linking can be based on
The general concept of additional information is independent of data pseudonymization. While one of the outputs of data pseudonymization is indeed (split-off)additional information, additional information can also exist independently and be held by other parties than the controller. Any data anywhere that permits (at least partial) identification of the pseudonymous data at hand is therefore considered to be additional information. |
Figure 12 illustrates how (general) additional information establishes a relation between data elements that uniquely match to the pseudonymous data on one end, and data elements that uniquely identify data subjects on the other. The figure also provided examples for such data elements.
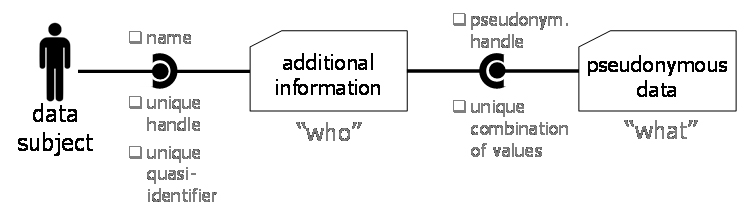
Figure 12: Additional information links pseudonymous data to a data subject.
| Definition: Split-off additional information
Split-off additional information is the additional information that results from data pseudonymization. Since it is designed to re-identify the pseudonymized data, on one side of the relation, it typically uses the pseudonym (or more precisely, the pseudonymous handle) to link to the (strictly)pseudonymous data. (This contrasts the general concept of additional information where such linking can also be based on unique combinations of values). On the other side of the relation, it typically uses a unique handle that is in use by the controller (such as a customer ID) to identify data subjects. While additional information in general identifies at least one data subject in the set of pseudonymous data, split-off additional information usually identifies all data subjects in the set of strictly pseudonymous data. |
While the above distinction of types of additional information was made based on the relationship of this information to the pseudonymization, types can also be distinguished based on the format of the information:
| Definition: Lookup-based additional information
Lookup-based additional information takes the form of a lookup table where every row, pertaining to a single data subject, contains both (one or several) directly identifying data elements and (one or several) data elements that permit linking to the pseudonymous data. The simplest form of lookup-based additional information consists of one column with a unique handle for data subjects and one with a pseudonym (i.e., pseudonymous handle, see below). Lookup-based additional information is always bi-directional (see definition below). |
Figure 13 gives an example for lookup-based additional information.
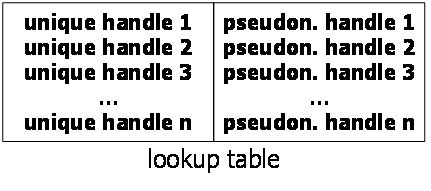
Figure 13: Lookup-based additional information.
| Definition: Formula-based additional information
Formula-based additional information takes the form of a function expressed by a formula whose input consists of (one or several) directly identifying data elements and whose output are (one or several) data elements that permit linking to the pseudonymous data. The simplest form of formula-based additional information takes a unique handle of data subjects as input and yields a pseudonym (i.e., pseudonymous handle, see below) as output. Note that an inverse function may or may not exist. In the example where the function is an encryption, the inverse function exists in the form of decryption. In the example where the function is a cryptographic one-way function (such as an HMAC), the inverse function does not exist. |
Figure 14 illustrates an example of formula-based additional information.
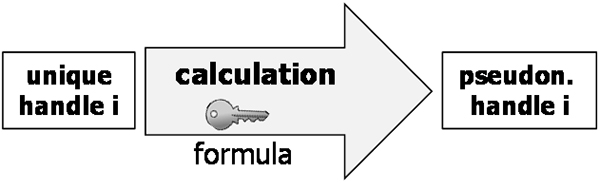
Figure 14: Formula-based additional information.
Additional information belongs to one of the two above types. Independently of this distinction, another independent distinction can be made:
| Definition: Bi-directional additional information
Bi-directional additional information permits to use the additional information to link in both directions:
Lookup-based additional information and encryption (i.e., an example of formula-based additional information) are examples for bi-directional additional information. |
| Definition: One-directional additional information
One-directional additional information permits the use of additional information only in one direction:
A typical example of one-directional additional information is a one-way function (such as a keyed HMAC). It usually maps a directly identifying unique handle of the data subject into a pseudonym (i.e., pseudonymous handle, see below) that can be linked to the pseudonymous data. Since a one-way function fails to have an inverse, it is not possible to inversely compute the unique handle of the data subject from the pseudonym. |
Figure 15 further illustrates the different types of additional information by providing common examples.
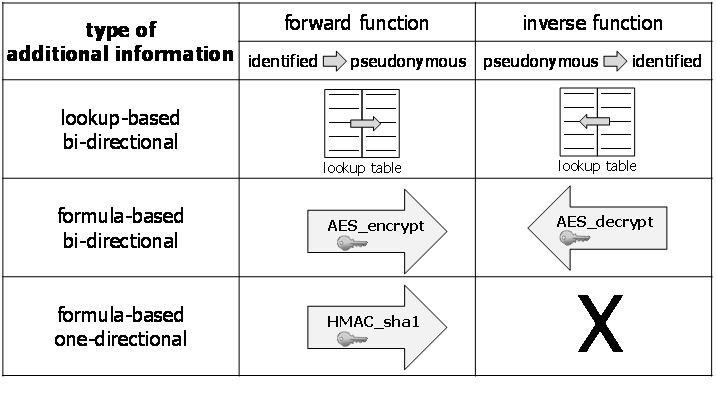
Figure 15: Examples of different types of additional information.
Also for the concept of pseudonyms, two types can be distinguished:
| Definition: (General) pseudonym [captures the common use of the term]
A general pseudonym or simply pseudonym is a data element that refers to a person without directly revealing the person’s identity. |
| Definition: Pseudonymous handle [captures the meaning in the context of pseudonymization]
A pseudonymous handle is a unique handle created in a separate identity domain with the sole purpose of creating a relation between split-off additional information and strictlypseudonymous data. This relation is established by inserting the pseudonymous handle in both, the split-off additional information and the strictlypseudonymous data. This enables easy deterministic linking based on equality matching. Since the pseudonymous handle’s identity domain is separate, it is impossible to link the pseudonymous handle to any other data sets but the strictlypseudonymous data and the split-off additional information. |
Note that technically, a pseudonymous handle is also a (general) pseudonym. Therefore, where it is clear from the context that the text is concerned with a pseudonymous handle, it can be simply referred to as pseudonym. With the exception of the above definition of general pseudonym, the present text is exclusively concerned with pseudonymous handles.
References
1The term “identified” seems a good description of the essence since the data contains both, the “who” and the “what”; if it contained only the “who”, “identifying” would likely be a better choice for the concept. ↑