Art. 4(5) chose to define pseudonymization in a very narrow manner. It is however useful to see it in its wider context which includes the processing of identified data that can precede pseudonymization and a possible re-identification of data that can occur after or in parallel to pseudonymization. For this purpose, Figure 6 illustrates the situation.
In the middle of the Figure, the representation of pseudonymization from Figure 5 can be recognized. Its elements are grouped into a box that represents the realm of pseudonymization. There are two transformations that lead in and out of the realm of pseudonymization. Namely, these are data pseudonymization and re-identification. Both will be defined in more detail below. These transformations bridge between the realm of pseudonymization and that of processing of identified data. Both of these transformations require access to both the pseudonymous data and the additional information. In particular, data pseudonymization creates both by splitting identified data into a who and what part; and re-identification combines these two back into identified data.
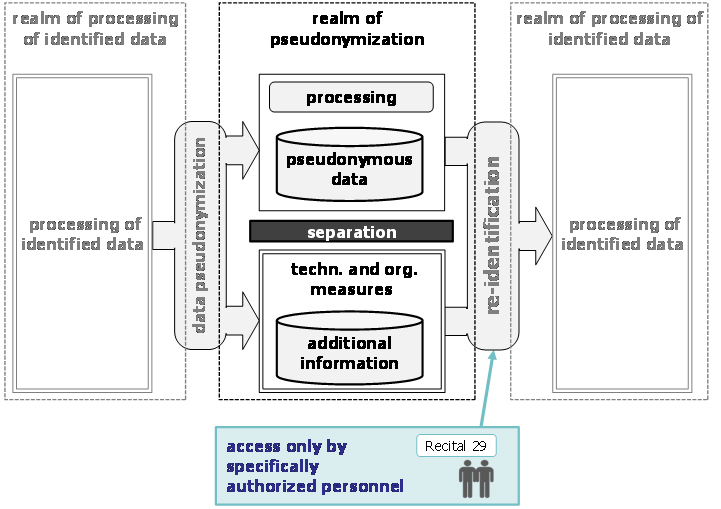
Figure 6: The context of pseudonymization.