Dans le document “Comprendre la protection des données : le règlement européen en quelques mots” ci-dessus, la limitation du stockage était motivée par la réduction du gain de pouvoir du responsable du traitement à ce qui est minimalement nécessaire pour réaliser les finalités déclarées et légitimes. En particulier, elle vise à réduire au minimum le degré d’association des données à caractère personnel avec la personne concernée. Cela complète la minimisation du contenu de l’information et la limitation de l’accès au pouvoir. Voir “Minimisation du pouvoir à ce qui est nécessaire pour réaliser les finalité déclarées” pour plus de détails.
Le RGPD définit ce principe comme suit :
| Définition de l’art. 5(1)(e) du RGPD :
Les données à caractère personnel sont conservées sous une forme permettant l’identification des personnes concernées pendant une durée n’excédant pas celle nécessaire à la réalisation des finalités pour lesquelles elles sont traitées ; […] (“limitation du stockage“) ; |
Il est clair que le concept principal de ce principe concerne l’identification, c’est-à-dire l’association des données personnelles à la personne concernée. Le reste de cette section analyse donc principalement ce que signifie réellement l’identification.
Notez que dans l’encadré de définition ci-dessus, la partie omise qui est représentée par […] a été discutée sous le principe de la minimisation des données (voir section “” dans “Minimisation des données”). Elle concerne la limitation temporelle du stockage qui est sans doute un aspect du concept général de limitation exprimé pour les données dans le principe de minimisation des données.
De ce point de vue, l’appellation “limitation du stockage” est trompeuse car elle implique uniquement l’aspect temporel de la minimisation des données et ne fait pas référence à l’identification dans son ensemble. Il serait peut-être plus clair de parler de minimisation du potentiel d’identification.
Identification des personnes concernées
Pour mieux comprendre ce que l’on entend par identification, nous nous référons à l’art. 4(1) duRGPD. La deuxième demi-phrase[1] se lit comme suit :
| [Une personne physique identifiable est une personne qui peut être identifiée, directement ou indirectement, notamment par référence à un identifiant tel qu’un nom, un numéro d’identification, des données de localisation, un identifiant en ligne ou à un ou plusieurs facteurs spécifiques à l’identité physique, physiologique, génétique, mentale, économique, culturelle ou sociale de cette personne physique ; |
Pour une meilleure compréhension, cette phrase est divisée en deux parties :
Identification directe par référence à un identifiant :
| [Une personne physique identifiable est une personne qui peut être identifiée, directement, notamment par référence à un identifiant tel qu’un nom, un numéro d’identification, des données de localisation, un identifiant en ligne ; |
Identification indirecte par référence à un ou plusieurs facteurs spécifiques à l’identité d’une personne physique :
| [Une personne physique identifiable est une personne qui peut être identifiée, indirectement, notamment par référence à un ou plusieurs facteurs spécifiques à l’identité physique, physiologique, génétique, mentale, économique, culturelle ou sociale de cette personne physique ; |
Les exemples d’identifiants sont[2] :
- Un nom,
- un numéro d’identification,
- les données de localisation,
- un identifiant en ligne.
Il convient de noter en particulier les données de localisation qui ne sont peut-être pas considérées comme un identifiant permettant une identification directe, même si leur caractère hautement identifiant est effectivement intuitif.
Les exemples de facteurs spécifiques à l’identité d’une personne physique concernent les aspects suivants :
- Physique,
- physiologique,
- génétique,
- mental,
- économique,
- culturel,
- sociale.
Cette distinction de l’identification directe et indirecte permet désormais de diversifier la notion de formulaire permettant l’identification des personnes concernées.
Types de données distingués dans le RGPD
Le RGPD distingue trois types de données avec différents degrés d’association avec les personnes concernées :
- les données personnelles directement identifiantes[3] ,
- les données personnelles pseudonymes, et
- les données anonymes.
(i) Données personnelles directement identifiantes : Le premier élément doit évidemment contenir des identifiants, puisqu’il permet l’identification directe des personnes concernées. La plupart des ensembles de données à caractère personnel ne contiennent cependant pas que des identifiants. Il faut alors considérer que les autres données sont toutes des éléments propres à l’identité d’une personne physique puisqu’elles décrivent toutes différents aspects liés à l’identité de la personne concernée.
(ii) Données personnelles pseudonymes : L’art. 4(5) du RGPD définit le concept connexe de “pseudonymisation”. Son libellé peut être adapté comme suit pour définir les données personnelles pseudonymes :
| Les données personnelles pseudonymes sont des données personnelles qui ne peuvent plus être attribuées à une personne concernée spécifique sans l’utilisation d’informations supplémentaires. |
Ceci doit être interprété de la manière suivante :
- Les données personnelles pseudonymes ne permettent pas une identification directe.
- Ellesne doivent donc pas contenir d’identifiants.
- Les données supplémentaires, dans ce contexte, sont des données qui permettent d’associer des facteurs spécifiques à l’identité d’une personne physique à des identifiants.
(iii) Données anonymes : Les informations anonymes sont définies au considérant 26 du RGPD (cinquième phrase). En utilisant l’information et les données comme synonymes, son libellé peut être adapté comme suit :
Les données anonymes sont soit
|
Notez que le terme “identifiable” recouvre à la fois l’identification directe et indirecte. Même avec des informations supplémentaires, il n’est pas possible d’attribuer des données anonymes à une personne spécifique.
Notez que selon le considérant 26 (phrase 6), le RGPD ne s’applique pas aux données anonymes. Cela est également clair puisqu’elles ne correspondent pas à la définition des données à caractère personnel (voir art. 4(1) et le considérant 26 du RGPD).
Après avoir distingué ces types de données, “conservées sous une forme permettant l’identification des personnes concernées pendant une durée n’excédant pas celle nécessaire à la réalisation des finalités” peut maintenant être compris de manière plus précise, en considérant également l’aspect temporel du principe.
Aspect temporel
L’art. 5(1)(e) aborde clairement l’aspect temporel en stipulant qu’un formulaire permettant l’identification doit être conservé pendant une durée n’excédant pas celle nécessaire à la réalisation des finalités. Cet aspect temporel est abordé ici de manière diversifiée. Les deux critères suivants définissent cette diversification :
- L’identification peut être directe ou indirecte.
- L’identification peut être accessible à tous ou à un groupe restreint de personnes.
Sur la base de ces distinctions, il est possible de distinguer quatre cas différents. Ceux-ci sont représentés comme des “phases”. Il est possible de passer d’une phase à n’importe quelle phase ultérieure. Cela peut se faire soit de manière séquentielle, soit en omettant les phases intermédiaires. Dans chaque phase, le degré d’identification des données avec la personne concernée est réduit. Le principe de limitation du stockagestipule qu’à tout moment, seul le degré minimal d’identification nécessaire à la réalisation des finalités doit être utilisé.
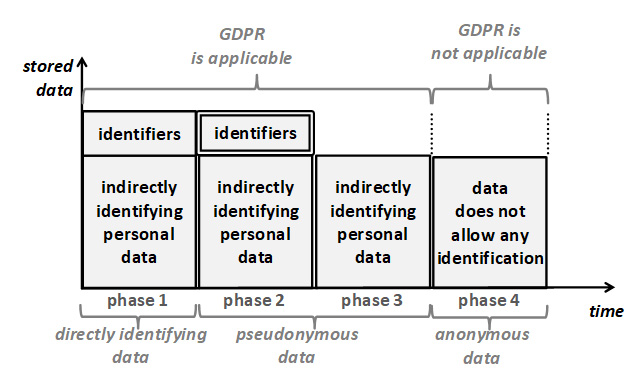
Figure 4: Données avec différents degrés d’association avec la personne concernée.
Il convient de noter que le principe de la limitation du stockageest présenté dans sa forme pure : le degré d’association avec la personne concernée est purement réduit entre deux phases consécutives. Dans la pratique, la limitation du stockage est généralement combinée avec la minimisation des données. Dans un scénario combiné, la hauteur des cases illustrées dans la figure serait également réduite.
Les phases de la figure sont décrites plus en détail dans ce qui suit :
La phase 1 montre les données qui contiennent à la fois des identifiants et des facteurs spécifiques à l’identité d’une personne physique. Par souci de concision, ces dernières sont appelées données personnelles directement identifiantes. Les identifiants permettent une identification directe. Elles sont accessibles à toute personne à qui les données sont divulguées.
La phase 2 présente un mode de traitement appelé “pseudonymisation“[4] . Dans ce cas, les identifiants sont toujours stockés, mais ils sont conservés séparément et protégés de manière à ce que l’accès ne soit possible que dans des conditions bien définies, selon des procédures prédéfinies, pour réaliser des finalités précisément définies, l’accès étant limité à un ensemble prédéfini de personnes autorisées[5] . Ces restrictions sont représentées par une double bordure autour des identifiants. L’accès à l’identification directe est donc étroitement contrôlé et n’est accessible qu’à quelques personnes désignées.
L’identification indirecte qui utilise des informations supplémentaires est toujours possible sur la base des données personnelles indirectement identifiantes. Elle nécessite toutefois des informations supplémentaires. Le responsable du traitement met en œuvre des mesures pour empêcher la disponibilité de ces informations supplémentaires pour les personnes qui accèdent à ces données pendant l’activité de traitement. Cela signifie que pour la grande partie du traitement (et un sous-ensemble important de finalités), et pour la majorité des employés, l’identification n’est plus possible.
La phase 3 montre la situation dans laquelle les finalités ne nécessitent plus la possibilité d’une identification directe des personnes concernées, même pas dans des cas exceptionnels. Dans ce cas, les identifiants qui permettent une identification directe peuvent être purement et simplement supprimés. Par conséquent, si des mesures de protection adéquates sont en place, le responsable du traitement lui-même (y compris l’ensemble du personnel) n’est plus en mesure d’identifier les personnes concernées. De toute évidence, cela réduit encore le degré d’identification par rapport à la phase 2.
La phase 4 montre que seules des données anonymes sont utilisées. Ce chiffre implique que celles-ci sont le résultat d’une anonymisation des données de la phase 3 (ou des phases précédentes). Par définition[6] , les données anonymes ne peuvent pas être attribuées à une personne concernée, même en utilisant des informations supplémentaires. Ces données ne sont donc plus des données à caractère personnel et ne sont donc pas soumises au RGPD (et une anonymisation réussie a donc le même effet qu’une suppression). Les données anonymes éliminent donc complètement la possibilité d’identification.
Certains lecteurs connaissent peut-être le concept de “non-liaison”[7] , qui est étroitement lié à celui de limitation de stockage. Cela devient clair si l’on considère que l’identification directe peut être considérée comme un identifiant établissant un lien avec la personne concernée ; et que l’utilisation d’informations supplémentaires pour l’identification indirecte nécessite de relier les enregistrements de données qui appartiennent à la même personne dans les deux ensembles de données.
- Une partie de phrase séparée du reste par un point-virgule est appelée ici “demi-phrase”. ↑
- Notez que le considérant 30 du RGPD fournit en outre des exemples d'”identifiants en ligne” : adresses de protocole internet, identifiants de cookies ou autres identifiants tels que les étiquettes d’identification par radiofréquence. ↑
- Le terme “données personnelles directement identifiantes” n’est pas utilisé dans le RGPD mais cloné par l’auteur. ↑
- Voir l’article 4, paragraphe 5, du RGPD. ↑
- Voir le considérant 29 du RGPD, 2nd phrase. ↑
- Voir le considérant 26 du RGPD. ↑
- Conférence allemande des autorités indépendantes de protection des données de la Fédération et des Länder, 17 avril 2020. Le modèle standard de protection des données, https://www.datenschutz-mv.de/static/DS/Dateien/Datenschutzmodell/SDM-Methode_V20b_EN.pdf (dernière visite le 28/05/2020). ↑