En Entendiendo la protección de datos: el reglamento de la UE en pocas palabras),la limitación del almacenamiento estaba motivada por la minimización de la ganancia de poder del responsable del tratamiento a lo mínimamente necesario para cumplir los fines legítimos declarados. En particular, se trataba de minimizar el grado de asociación de los datos personales con el interesado. Esto complementa la minimización del contenido de la información y la limitación del acceso al poder. Véase Minimización del poder a lo necesario para cumplir los fines declarados para más detalles.
El RGPD define el principio de la siguiente manera:
| Definición en el Art. 5(1)(e) del RGPD:
Los datos personales se conservarán en una forma que permita la identificación de los interesados durante un período no superior al necesario para los fines para los que se tratan los datos personales; […] (“limitación de almacenamiento“); |
Evidentemente, el concepto principal de este principio se refiere a la identificación, es decir, a la asociación de los datos personales con su titular. Por lo tanto, el resto de esta sección analiza principalmente lo que significa realmente la identificación.
Obsérvese que, en el recuadro de definición anterior, la parte omitida que se representa con […] se ha tratado bajo el principio de minimización de datos). Se trata de la limitación temporal del almacenamiento, que podría ser un aspecto del concepto general de limitación expresado para los datos en el principio de minimización de datos.
Desde este punto de vista, el nombre de limitación del almacenamiento es engañoso, ya que implica únicamente el aspecto temporal de la minimización de datos, pero no se refiere a la identificación en su totalidad. Llamarla minimización del potencial de identificación puede ser más claro.
Identificación de los interesados
Para entender mejor lo que se entiende por identificación, nos remitimos al art. 4(1) DEL RGPD. La segunda media[1] frase dice lo siguiente:
| [Una persona física identificable es aquella que puede ser identificada, directa o indirectamente, en particular por referencia a un identificador como un nombre, un número de identificación, datos de localización, un identificador en línea o a uno o más factores específicos de la identidad física, fisiológica, genética, mental, económica, cultural o social de dicha persona física; |
Para una mejor comprensión, esta frase se divide en las dos partes siguientes:
Identificación directa por referencia a un identificador:
| [Una persona física identificable es aquella que puede ser identificada, directa, en particular por referencia a un identificador como un nombre, un número de identificación, datos de localización, un identificador en línea; |
Identificación indirecta por referencia a uno o más factores específicos de la identidad de una persona física:
| [Una persona física identificable es aquella que puede ser identificada, indirectamente, en particular por referencia a uno o más factores específicos de la identidad física, fisiológica, genética, mental, económica, cultural o social de dicha persona física; |
Los ejemplos de identificadores son[2]:
- Un nombre,
- un número de identificación,
- datos de localización,
- un identificador en línea.
Obsérvese, en particular, que los datos de localización no suelen considerarse un identificador que permita la identificación directa, aunque su carácter altamente identificativo sea efectivamente intuitivo.
Los ejemplos de factores específicos de la identidad de una persona física se refieren a los siguientes aspectos:
- Físico,
- fisiológico,
- genética,
- mental,
- económico,
- cultural,
- social.
Esta distinción entre identificación directa e indirecta permite ahora diversificar el concepto de forma que permite la identificación de los interesados.
Tipos de datos distinguidos en el RGPD
El RGPD distingue tres tipos de datos con diferentes grados de asociación con los interesados:
- datos[3] personales directamente identificables,
- datos personales seudónimos, y
- datos anónimos.
(i) Datos personales directamente identificables: El primero evidentemente debe contener identificadores, ya que permite la identificación directa de los interesados. Sin embargo, la mayoría de los conjuntos de datos personales no sólo contienen identificadores. Los demás datos deben considerarse entonces como factores específicos de la identidad de una persona física, ya que todos ellos describen aspectos diferentes que están vinculados a la identidad del interesado.
(ii) Datos personales seudónimos: El art. 4(5) del RGPD define el concepto relacionado de “seudonimización”. Su redacción puede adaptarse como sigue para definir los datos personales seudónimos:
| Los datos personales seudónimos son datos personales que ya no pueden atribuirse a un sujeto de datos específico sin el uso de información adicional. |
Esto debe interpretarse de la siguiente manera:
- Los datos personales seudónimos no pueden servir para la identificación directa.
- Por lo tanto, no debe contener identificadores.
- Los datos adicionales, en este contexto, son datos que permiten asociar factores específicos de la identidad de una persona física con identificadores.
(iii) Datos anónimos: La información anónima se define en el considerando 26 del RGPD (quinta frase). Utilizando información y datos como sinónimos, su redacción puede adaptarse como sigue:
Los datos anónimos son
|
Obsérvese que la identificación comprende tanto la directa como la indirecta. Incluso con información adicional, no es posible atribuir los datos anónimos a un sujeto de datos específico.
Obsérvese que, según el considerando 26 (frase 6), el RGPD no se aplica a los datos anónimos. Esto también está claro ya que no coincide con la definición de datos personales (véase el Art. 4(1) y el considerando 26 del RGPD).
Habiendo distinguido estos tipos de datos, “conservados en una forma que permita la identificación de los interesados durante un período no superior al necesario para los fines” puede entenderse ahora con mayor precisión, considerando también el aspecto temporal del principio.
Aspecto temporal
El art. 5(1)(e) aborda claramente el aspecto temporal al ordenar que un formulario que permita la identificación no se conserve más tiempo del necesario para sus fines. Este aspecto temporal se trata aquí de forma diversificada. Los dos criterios siguientes definen esta diversificación:
- La identificación puede ser directa o indirecta.
- La identificación puede ser accesible para todos o para un grupo restringido de personas.
Sobre la base de estas distinciones, es posible distinguir cuatro casos diferentes. Estos se muestran en Figura 4 representados como “fases”. Es posible pasar de una fase a otra posterior. Esto puede hacerse de forma secuencial, o bien omitiendo las fases intermedias. En cada fase se reduce el grado de identificación de los datos con el interesado. El principio de limitación del almacenamiento establece que, en cualquier momento, sólo debe utilizarse el grado mínimo de identificación que sea necesario para cumplir los fines.
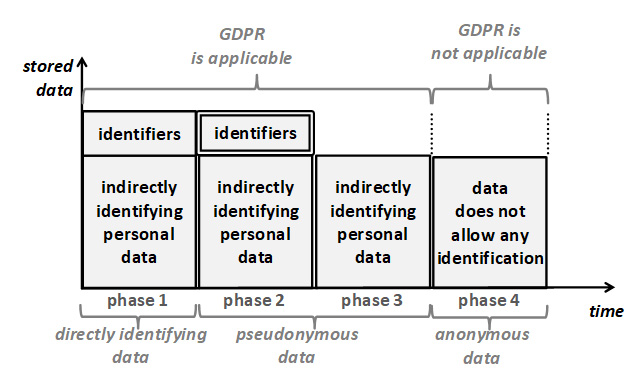 Figura 4: Datos con diferentes grados de asociación con el sujeto de los datos.
Figura 4: Datos con diferentes grados de asociación con el sujeto de los datos.
Obsérvese que el principio de limitación del almacenamiento se muestra en su forma pura: En estado puro, el grado de asociación con el sujeto de los datos se reduce entre fases consecutivas. En la práctica, la limitación del almacenamiento suele combinarse con la minimización de los datos. En un escenario combinado, la altura de las cajas mostradas en la figura también se reduciría.
Las fases de la figura se describen con más detalle a continuación:
La fase 1 muestra los datos que contienen tanto identificadores como factores específicos de la identidad de una persona física. Para abreviar, estos últimos se denominan datos personales de identificación indirecta. Los identificadores permiten la identificación directa. Son accesibles a cualquier persona a la que se revelen los datos.
La fase 2 muestra una forma de tratamiento denominada “seudonimización“[4]. En este caso, los identificadores se siguen almacenando, pero se guardan por separado y se protegen de manera que sólo se pueda acceder a ellos en condiciones bien especificadas, utilizando procedimientos predefinidos, para lograr fines definidos con precisión, con acceso restringido a un conjunto predefinido de personas autorizadas[5]. Estas restricciones se representan mediante un doble borde alrededor de los identificadores. De este modo, el acceso a la identificación directa está estrechamente controlado y sólo está disponible para unas pocas personas designadas.
La identificación indirecta que utiliza información adicional sigue siendo posible a partir de los datos personales de identificación indirecta. Sin embargo, requiere información adicional. El responsable del tratamiento aplica medidas para evitar que las personas que acceden a estos datos durante la actividad de tratamiento dispongan de dicha información adicional. Esto significa que para la mayor parte del tratamiento (y un subconjunto importante de fines), y la mayoría de los empleados, la identificación ya no es posible.
La fase 3 muestra la situación en la que los fines ya no requieren la posibilidad de identificar directamente a los interesados, ni siquiera en casos excepcionales. En este caso, los identificadores que permiten la identificación directa pueden suprimirse por completo. En consecuencia, con las medidas de protección adecuadas, el propio responsable del tratamiento (incluido todo el personal) ya no puede identificar a los interesados. Evidentemente, esto reduce aún más el grado de identificación en comparación con la fase 2.
La fase 4 muestra que sólo se utilizan datos anónimos. La figura implica que éstos son el resultado de una anonimización de los datos de la fase 3 (o de fases anteriores). Por definición[6], los datos anónimos no pueden atribuirse a un interesado, ni siquiera con el uso de información adicional. Por lo tanto, estos datos ya no son datos personales y, por lo tanto, no están sujetos al RGPD (y, por lo tanto, la anonimización exitosa tiene el mismo efecto que la eliminación). Por lo tanto, los datos anónimos eliminan por completo la posibilidad de identificación.
Algunos lectores pueden conocer el concepto de “desvinculación” [7]que está estrechamente relacionado con el de limitación de almacenamiento. Esto queda claro cuando se considera que la identificación directa puede verse como un identificador que establece un vínculo con el sujeto de los datos; y que el uso de información adicional para la identificación indirecta requiere vincular registros de datos que pertenecen a la misma persona en los dos conjuntos de datos.
- La parte de una frase que se separa del resto con punto y coma se denomina aquí “media frase”. ↑
- Obsérvese que el considerando 30 del RGPD ofrece además ejemplos de “identificadores en línea”: direcciones de protocolo de Internet, identificadores de cookies u otros identificadores como etiquetas de identificación por radiofrecuencia. ↑
- El término “datos personales de identificación directa” no se utiliza en el RGPD, sino que es clonado por el autor. ↑
- Véase el artículo 4, apartado 5, del RGPD. ↑
- Véase el considerando 29 del RGPD, segunda frase. ↑
- Véase el considerando 26 del RGPD. ↑
- Conferencia Alemana de las Autoridades Independientes de Protección de Datos de la Federación y de los Länder, 17. Abril de 2020, El modelo estándar de protección de datos, https://www.datenschutz-mv.de/static/DS/Dateien/Datenschutzmodell/SDM-Methode_V20b_EN.pdf (última visita: 28/05/2020). ↑