In Capire la protezione dei dati: il regolamento UE in poche parole, la limitazione della conservazione era motivata dalla minimizzazione del guadagno di potere del titolare del trattamento a quello che è minimamente necessario per soddisfare le finalità dichiarate e legittime. In particolare, ha affrontato la minimizzazione del grado in cui i dati personali sono associati al soggetto dei dati. Questo completa la minimizzazione del contenuto dell’informazione e la limitazione dell’accesso al potere. Vedi Minimizzazione del potere a ciò che è necessario per soddisfare le finalità dichiarate per il dettaglio.
Il GDPR definisce il principio come segue:
| Definizione nell’art. 5(1)(e) GDPR:
I dati personali sono conservati in una forma che consenta l’identificazione delle persone interessate per un tempo non superiore a quello necessario per le finalità per le quali i dati personali sono trattati; […] (“limitazione della conservazione“); |
Chiaramente, il concetto principale di questo principio riguarda l’identificazione, cioè l’associazione dei dati personali con la persona interessata. Il resto di questa sezione analizza quindi principalmente cosa significa effettivamente l’identificazione.
Si noti che nel riquadro di definizione di cui sopra, la parte omessa che è rappresentata da […] è stata discussa sotto il principio di minimizzazione dei dati (vedi 1.3). Essa riguarda la limitazione temporale della memorizzazione che è probabilmente un aspetto del concetto generale di limitazione espresso per i dati nel principio di minimizzazione dei dati.
Da questo punto di vista, il nome di limitazione della conservazione è fuorviante poiché implica solo l’aspetto temporale della minimizzazione dei dati ma non si riferisce all’identificazione. Chiamarla minimizzazione del potenziale di identificazione potrebbe essere più chiaro.
Identificazione delle persone interessate
Per capire meglio cosa si intende per identificazione, facciamo riferimento all’art. 4(1) GDPR. La seconda metà[1] della frase recita come segue:
| [Una persona fisica identificabile è una persona che può essere identificata, direttamente o indirettamente, in particolare mediante riferimento a un identificatore come un nome, un numero di identificazione, dati relativi all’ubicazione, un identificatore online o a uno o più fattori specifici dell’identità fisica, fisiologica, genetica, mentale, economica, culturale o sociale di tale persona fisica; |
Per una migliore comprensione, questa frase è divisa nelle due parti seguenti:
Identificazione diretta con riferimento a un identificatore:
| [Una persona fisica identificabile è una persona che può essere identificata, direttamente, in particolare mediante riferimento a un identificatore come un nome, un numero di identificazione, dati relativi all’ubicazione, un identificatore online ; |
Identificazione indiretta con riferimento a uno o più fattori specifici dell’identità di una persona fisica:
| [Una persona fisica identificabile è una persona che può essere identificata, indirettamente, in particolare mediante riferimento a uno o più fattori specifici dell’identità fisica, fisiologica, genetica, mentale, economica, culturale o sociale di tale persona fisica; |
Gli esempi per gli identificatori sono[2]
- Un nome,
- un numero di identificazione,
- dati di localizzazione,
- un identificatore online.
Si noti in particolare i dati di localizzazione che molti non sono comunemente pensati come un identificatore che supporta l’identificazione diretta, anche se il suo carattere altamente identificativo è effettivamente intuitivo.
Gli esempi di fattori specifici dell’identità di una persona fisica riguardano i seguenti aspetti:
- Fisico
- Fisiologico
- Genetico
- Mentale
- Economico
- Culturale
- Sociale
Questa distinzione di identificazione diretta e indiretta permette ora di diversificare il concetto di forma che permette l’identificazione degli interessati.
Tipi di dati distinti nel GDPR
Il GDPR distingue tre tipi di dati con diversi gradi di associazione con gli interessati:
- identificare direttamente i dati personali[3]
- dati personali pseudonimi
- dati anonimi
(i) Dati personali che identificano direttamente: Il primo deve evidentemente contenere identificatori, poiché permette l’identificazione diretta degli interessati. Tuttavia, la maggior parte delle serie di dati personali non contiene solo identificatori. Gli altri dati devono poi essere considerati tutti fattori specifici dell’identità di una persona fisica, poiché tutti descrivono aspetti diversi che sono legati all’identità della persona interessata.
(ii) Dati personali pseudonimi: L’art. 4(5) GDPR definisce il relativo concetto di “pseudonimizzazione”. La sua formulazione può essere adattata come segue per definire i dati personali pseudonimi:
| I dati personali pseudonimi sono dati personali che non possono più essere attribuiti a un soggetto specifico senza l’uso di informazioni aggiuntive. |
Questo deve essere interpretato nel modo seguente:
- I dati personali pseudonimi non possono supportare l’identificazione diretta.
- Non deve quindi contenere identificatori.
- I dati aggiuntivi, in questo contesto, sono dati che permettono di associare agli identificatori fattori specifici dell’identità di una persona fisica.
(iii) Dati anonimi: Leinformazioni anonime sono definite nel considerando 26 del GDPR (quinta frase). Usando informazioni e dati come sinonimi, la sua formulazione può essere adattata come segue:
I dati anonimi sono
|
Si noti che l’identificabile comprende sia l’identificazione diretta che quella indiretta. Anche con informazioni aggiuntive, non è possibile attribuire dati anonimi a un soggetto specifico.
Si noti che secondo il considerando 26 (frase 6), il GDPR non si applica ai dati anonimi. Questo è chiaro anche perché non corrisponde alla definizione di dati personali (vedi Art. 4(1) e il considerando 26 del GDPR).
Avendo distinto questi tipi di dati, “conservati in una forma che permetta l’identificazione delle persone interessate per un tempo non superiore a quello necessario alle finalità” può essere ora inteso in modo più preciso, considerando anche l’aspetto temporale del principio.
Aspetto temporale
L’art. 5(1)(e) affronta chiaramente l’aspetto temporale imponendo che un modulo che permette l’identificazione non sia conservato più a lungo di quanto sia necessario per gli scopi. Questo aspetto temporale è discusso qui in modo diversificato. I due criteri seguenti definiscono questa diversificazione:
- L’identificazione può essere diretta o indiretta.
- L’identificazione può essere accessibile a tutti o a un gruppo ristretto di persone.
Sulla base di queste distinzioni, è possibile distinguere quattro casi diversi. Questi sono mostrati in Figura 4 rappresentati come “fasi”. È possibile passare da una fase a qualsiasi fase successiva. Questo può essere fatto sia in modo sequenziale, sia omettendo le fasi intermedie. In ogni fase, il grado di identificazione dei dati con la persona interessata si riduce. Il principio di limitazione della memorizzazione afferma che in ogni momento, solo il grado minimo di identificazione che è necessario per soddisfare gli scopi deve essere utilizzato.
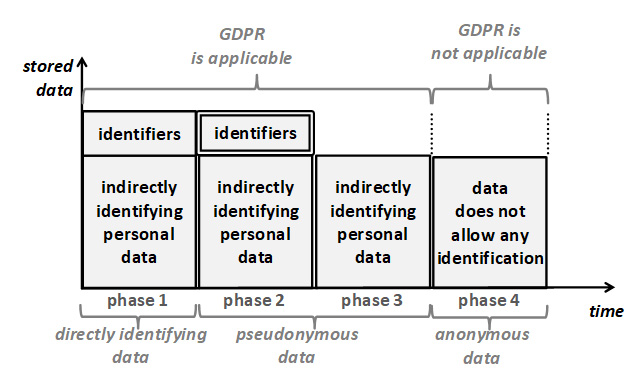
Figura 4: Dati con diversi gradi di associazione con il soggetto dei dati.
Si noti che il principio della limitazione della conservazione è mostrato nella sua forma pura: il grado di associazione con il soggetto dei dati è ridotto tra fasi consecutive. In pratica, la limitazione della memorizzazione è generalmente combinata con la minimizzazione dei dati. In uno scenario combinato, anche l’altezza delle caselle mostrate in figura sarebbe ridotta.
Le fasi della figura sono descritte più in dettaglio nel seguito:
La fase 1 mostra i dati che contengono entrambi, identificatori e fattori specifici dell’identità di una persona fisica. Per brevità, questi ultimi sono chiamati dati personali indirettamente identificativi. Gli identificatori supportano l’identificazione diretta. Sono accessibili a tutti coloro ai quali i dati vengono divulgati.
La fase 2 mostra una modalità di trattamento chiamata “pseudonimizzazione“[4]. Qui, gli identificatori sono ancora memorizzati, ma tenuti separati e protetti in un modo che consente l’accesso solo in condizioni ben specificate, utilizzando procedure predefinite, per raggiungere scopi precisamente definiti, con accesso limitato a un insieme predefinito di persone[5] autorizzate. Queste restrizioni sono rappresentate da un doppio bordo intorno agli identificatori. L’accesso all’identificazione diretta è quindi strettamente controllato e disponibile solo a poche persone designate.
L’identificazione indiretta che utilizza informazioni aggiuntive è ancora possibile sulla base dei dati personali che identificano indirettamente. Richiede tuttavia informazioni aggiuntive. Il titolare del trattamento implementa misure per prevenire la disponibilità di tali informazioni aggiuntive alle persone che accedono a questi dati durante l’attività di trattamento. Ciò significa che per la maggior parte dei trattamenti (e un importante sottoinsieme di scopi), e la maggior parte dei dipendenti, l’identificazione non è più possibile.
La fase 3 mostra la situazione in cui le finalità non richiedono più la possibilità di identificazione diretta degli interessati, nemmeno in casi eccezionali. In questo caso, gli identificatori che permettono l’identificazione diretta possono essere cancellati del tutto. Di conseguenza, con adeguate misure di protezione in atto, il titolare del trattamento stesso (compreso tutto il personale) non è più in grado di identificare gli interessati. Questo evidentemente riduce ulteriormente il grado di identificazione rispetto alla fase 2.
La fase 4 mostra che vengono utilizzati solo dati anonimi. La figura implica che questi sono il risultato di un’anonimizzazione dei dati della fase 3 (o delle fasi precedenti). Per definizione[6], i dati anonimi non possono essere attribuiti a una persona interessata, nemmeno con l’uso di informazioni aggiuntive. Questi dati non sono quindi più dati personali e quindi non sono soggetti al GDPR (e l’anonimizzazione riuscita ha quindi lo stesso effetto della cancellazione). I dati anonimi eliminano quindi completamente la possibilità di identificazione.
Alcuni lettori potrebbero conoscere il concetto di “unlinkability“[7] che è strettamente legato a quello di limitazione della conservazione. Questo diventa chiaro quando si considera che l’identificazione diretta può essere vista come un identificatore che stabilisce un legame con il soggetto dei dati; e che l’uso di informazioni aggiuntive per l’identificazione indiretta richiede di collegare i record di dati che appartengono alla stessa persona nelle due serie di dati.
- Una parte di frase che è separata dal resto con punti e virgola è qui chiamata “mezza frase”. ↑
- Si noti che il considerando 30 del GDPR fornisce inoltre esempi di “identificatori online”: indirizzi di protocollo internet, identificatori di cookie o altri identificatori come i tag di identificazione a radiofrequenza. ↑
- Il termine “dati personali che identificano direttamente” non è usato nel GDPR ma clonato dall’autore. ↑
- Vedi articolo 4(5) GDPR. ↑
- Vedi considerando 29 GDPR, 2ªfrase. ↑
- Vedi il considerando 26 del GDPR. ↑
- Conferenza tedesca delle autorità indipendenti di protezione dei dati della Federazione e dei Länder, 17. Aprile 2020, Il modello standard di protezione dei dati, https://www.datenschutz-mv.de/static/DS/Dateien/Datenschutzmodell/SDM-Methode_V20b_EN.pdf (ultima visita 28/05/2020). ↑