In Understanding data protection: the EU regulation in a nutshell above, storage limiation was motivated by minimizing the power gain of the controller to that what is minimally necessary to fulfill the declared, legitimate purposes. In particular, it addressed the minimization of the degree to which the personal data is associated with the data subject. This complements the minimization of the information content and the limitation of access to power. See Minimization of power to what is necessary to fulfill the declared purposes for detail.
The GDPR defines the principle as follows:
| Definition in Art.5(1)(e) GDPR:
Personal data shall be kept in a form which permits identification of data subjects for no longer than is necessary for the purposes for which the personal data are processed; […] |
Clearly, the main concept of this principle is concerned with the identification, i.e., the association of the personal data with its data subject. The remainder of this section therefore mostly analyzes what identification actually means.
Note that in the definition box above, the omitted part that is represented by […] has been discussed under the principle of data minimization (see Related articles and recitals in Data minimization ). It is concerned with the temporal limitation of the storage which is arguably one aspect of the general concept of limitation expressed for data in the principle of data minimization.
From this point of view, the name storage limitation is misleading since it implies solely the temporal aspect of data minimization but fails to refer to identification altogether. Calling it minimization of identification potential may be clearer.
Identification of data subjects
To better understand what is meant by identification, we refer to Art. 4(1) GDPR. The second half-sentence[1] reads as follows:
| [A]n identifiable natural person is one who can be identified, directly or indirectly, in particular by reference to an identifier such as a name, an identification number, location data, an online identifier or to one or more factors specific to the physical, physiological, genetic, mental, economic, cultural or social identity of that natural person; |
For better understanding, this sentence is split into the following two parts:
Direct identification by reference to an identifier:
| [A]n identifiable natural person is one who can be identified, directly, in particular by reference to an identifier such as a name, an identification number, location data, an online identifier; |
Indirect identification by reference to one or more factors specific to the identity of a natural person:
| [A]n identifiable natural person is one who can be identified, indirectly, in particular by reference to one or more factors specific tothephysical, physiological, genetic, mental, economic, cultural or social identity of that natural person; |
The examples for identifiers are[2]:
- A name,
- an identification number,
- location data,
- an online identifier.
Note particularly location data that may not commonly be thought of as an identifier that supports direct identification, even if its highly identifying character is indeed intuitive.
The examples for factors specific to the identity of a natural person concern the following aspects:
- Physical,
- physiological,
- genetic,
- mental,
- economic,
- cultural,
- social.
This distinction of direct and indirect identification now allows diversifying the concept of a form which permits identification of data subjects.
Types of data distinguished in the GDPR
The GDPR distinguishes three kinds of data with different degrees of association with data subjects:
- directly identifying personal data[3],
- pseudonymous personal data, and
- anonymous data.
(i) Directly Identifying Personal Data: The first evidently must contain identifiers, since it permits direct identification of data subjects. Most personal data sets contain not only identifiers, though. The other data must then be considered to be all factors specific to the identity of a natural person since they all describe different aspect that are linked to the identity of the data subject.
(ii) Pseudonymous Personal Data: Art. 4(5) GDPR defines the related concept of “pseudonymization”. Its wording can be adapted as follows to define pseudonymous personal data:
| Pseudonymous personal data is personal data that can no longer be attributed to a specific data subject without the use of additional information. |
This must be interpreted in the following manner:
- Pseudonymous personal data cannot support direct identification.
- It therefore must not contain identifiers.
- Additional data, in this context, is data that permits to associate factors specific to the identity of a natural person with identifiers.
(iii) Anonymous Data: Anonymous information are defined in Recital 26 GDPR (fifth sentence). Using information and data synonymously, its wording can be adapted as follows:
Anonymous data is either
|
Note that identifiable here comprises both, direct and indirect identification. Even with additional information, it is not possible to attribute anonymous data to a specific data subject.
Note that according to the Recital 26 (sentence 6), the GDPR does not apply to anonymous data. This is also clear since it does not match the definition of personal data (see Art. 4(1) and Recital 26 GDPR).
Having distinguished these types of data, “kept in a form which permits identification of data subjects for no longer than is necessary for the purposes”can now be understood more precisely, considering also the temporal aspect of the principle.
Temporal aspect
Art. 5(1)(e) clearly addresses the temporal aspect by mandating, that a form that a form which permits identification shall be kept for no longer than is necessary for the purposes. This temporal aspect is discussed here in a diversified manner. The following two criteria define this diversification:
- Identification can be either direct or indirect.
- Identification can be accessible to everyone or to a restricted group of people.
Based on these distinctions, it is possible to distinguish four different cases. These are shown in Figure 4 represented as “phases”. It is possible to transition from one phase to any later phase. This can be done either sequentially, or by omitting intermediate phases. In every phase, the degree of identification of the data with the data subject is reduced. The principle of storage limitation states that at any moment, only the minimal degree of identification that is necessary to fulfill the purposes must be used.
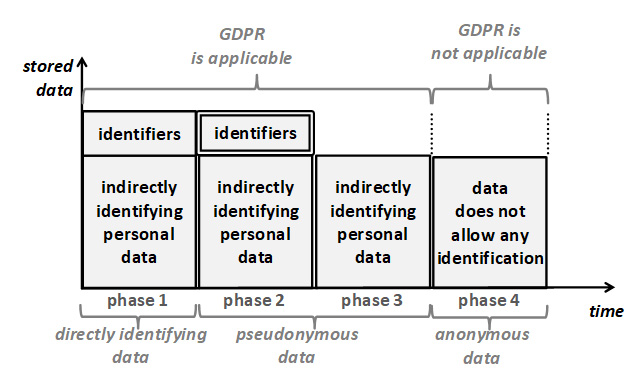
Figure 4: Data with different degrees of association with data subject.
Note that the principle of storage limitation is shown in its pure form: Purely the degree of association with the data subject is reduced between consecutive phases. In practice, storage limitation is typically combined with data minimization. In a combined scenario, the height of the boxes shown in the figure would also be reduced.
The phases of the figure are described in more detail in the following:
Phase 1 shows the data that contain both, identifiers and factors specific to the identity of a natural person. For brevity, the latter are called indirectly identifying personal data. The identifiers support direct identification. It is accessible to anybody to whom the data is disclosed.
Phase 2 shows a manner of processing called “pseudonymization”[4]. Here, the identifiers are still stored, but kept separately and protected in a manner that enables access only under well-specified conditions, using pre-defined procedures, for achieving precisely defined purposes, with access restricted to a predefined set of authorized persons[5]. These restrictions are depicted by a double border around the identifiers. The access to direct identification is thus closely controlled and available only to few designated persons.
Indirect identification that uses additional information is still possible based on the indirectly identifying personal data. It requires additional information, however. The controller implements measures to prevent the availability of such additional information to the persons who access this data during the processing activity. This means that for the large part of processing (and an important subset of purposes), and the majority of employees, identification is no longer possible.
Phase 3 shows the situation where the purposes no longer require the possibility of direct identification of data subjects, not even in exceptional cases. In this case, the identifiers that allow direct identification can be deleted altogether. Consequently, with adequate protection measures in place, the controller itself (including all staff) is no longer able to identify the data subjects. This evidently reduces the degree of identification further compared to phase 2.
Phase 4 shows that only anonymous data are used. The figure implies that these are the result of an anonymization of the data of phase 3 (or earlier phases). By definition[6], anonymous data cannot be attributed to a data subject, not even with the use of additional information. This data is therefore no longer personal data and thus not subject to the GDPR (and successful anonymization therefore has the same effect as deletion). Anonymous data therefore completely eliminates the possibility of identification.
Some readers may know the concept of “unlinkability”[7] that is closely related to that of storage limitation. This becomes clear when considering that direct identification can be seen as an identifier establishing a link to the data subject; and that the use of additional information for indirect identification requires to link data records that belong the same person in the two data sets.
References
1A part of a sentence that is separated from the rest with semicolons is here referred to as “half-sentence”. ↑
2Note that Recital 30 GDPR provides in addition examples for “online identifiers”: internet protocol addresses, cookie identifiers or other identifiers such as radio frequency identification tags. ↑
3The term “directly identifying personal data” is not used in the GDPR but cloned by the author. ↑
4See Article 4(5) GDPR. ↑
5See Recital 29 GDPR, 2nd sentence. ↑
6See Recital 26 GDPR. ↑
7German Conference of the Independent Data Protection Authorities of the Federation and the Länder, 17. April 2020, The Standard Data Protection Model, https://www.datenschutz-mv.de/static/DS/Dateien/Datenschutzmodell/SDM-Methode_V20b_EN.pdf (last visited 28/05/2020). ↑